For two strings s and t, we say “t divides s” if and only if s = t + ... + t (i.e., t is concatenated with itself one or more times).
Given two strings str1 and str2, return the largest string x such that x divides both str1 and str2.
I initially solved this like this:
string gcdOfStrings(string str1, string str2) { int minlen = min(str1.size(), str2.size()); // check if one is substring of another. if not, return "". if (str1.substr(0, minlen) != str2.substr(0, minlen)) { return ""; } for (int i = minlen; i > 0; i--) { // if str1 and str2 are not divisible by i, pass if (! (str1.size() % i == 0 && str2.size() % i == 0)) { continue; } // check if GCD is correct string GCD = str1.substr(0, i); for (int j = 0; j < str1.size(); j+=i) { if (GCD != str1.substr(j, i)) goto pass; } for (int j = 0; j < str2.size(); j+=i) { if (GCD != str2.substr(j, i)) goto pass; } return GCD; pass: ; } return ""; }
But there was a simpler logic:
str1 and str2 have a gcd iffstr1+str2 == str2+str1
I was solving 169. Majority Element and was struggling to find a one passalgorithm with O(1) space (these are called streaming algorithms). The best I could figure out was in O(n^2) time + O(1) space or O(nlogn) time + O(n) space. But then I saw this mind-blowing one pass approach called MJRTY – Vast Majority Vote Algorithm by Boyer and Moore.
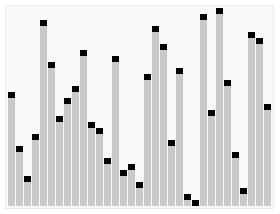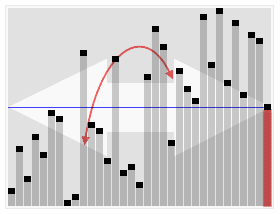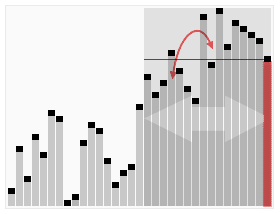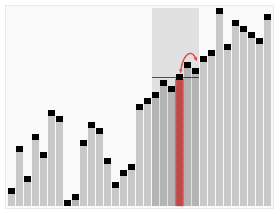
The approach becomes evident with the image below:
We start counting the first element, if a different element appears, instead of start counting that, we decrease the current count. When count becomes 0, we start counting whatever element we encounter next. At the end of the iteration, what we are left with is the majority element.
This only works when an element appears more than n/2 times through the array. The why is pretty intuitive and logical.
Implementation
int majorityElement(vector<int>& nums) { int x, cnt = 0; for (int i = 0; i < nums.size(); i++){ if (cnt == 0){ x = nums[i]; cnt++; } else{ if (nums[i] == x) cnt++; else cnt--; } } return x; }
or faster if written like this:
int majorityElement(vector<int>& nums) { int x = nums[0]; int cnt = 1; for(int i=1;i<nums.size();i++){ if(nums[i] == x){ cnt++; } else{ cnt--; } if(cnt == 0){ x = nums[i]; cnt = 1; } } return x; }
But this has drawbacks. Memory is wasted every time we dequeue.
Thus, need a circular queue.
Circular Queue
fixed-size array, 2 pointers indicating head and tail. Goal is to reuse the wasted storage.
In designing a DS, it’s good to have as few attributes as possible and maintain a simple manipulation logic. Sometimes, there can be some redundancy to minimize time complexity.
Attributes:
queue: fixed size array.
headIndex: integer which indicates the current head element
count: the current length. with `headIndex`, we can locate the tail element.
capacity: max number of elements that can be held in the queue. With this, we reduce TC for calling len(queue).
class MyCircularQueue { private: vector<int> data; int head; int tail; int size; public: MyCircularQueue(int k) { data.resize(k); head = -1; tail = -1; size = k; } bool enQueue(int value) { if (isFull()) { return false; } if (isEmpty()) { head = 0; } tail = (tail + 1) % size; data[tail] = value; return true; } bool deQueue() { if (isEmpty()) { return false; } if (head == tail) { head = -1; tail = -1; return true; } head = (head + 1) % size; return true; } int Front() { if (isEmpty()) { return -1; } return data[head]; } int Rear() { if (isEmpty()) { return -1; } return data[tail]; } bool isEmpty() { return head == -1; } bool isFull() { return ((tail + 1) % size) == head; } };
Hoare’s selecting algorithm is a textbook algorithm used to solve “find kth something”: kth smallest, kth largest, kth most frequent, kth less frequent, etc.
In a hashmap of <element, frequency>, select a random pivot point and use a partition scheme to place the pivot into a position where less frequent elements come to left side of pivot and more or equally frequent comes to the right.
If pivot index is N-k, there are k elements to the right side and all those are more or equally frequent elements, so return them. Else, choose the side of the array to proceed recursively.
Lomuto’s Partition Scheme
places elements >= pivot in the right side of pivot and elements < pivot in the left side.
swap the pivot with last element (or just start with the end element being pivot)
start a pointer from the left (index 0). Call this store_index.
iterating from 0 to end, if the element is less than pivot val, swap the element with element at store_index. If the element is >= pivot val, just pass.
After the iteration, swap pivot with element at store_index (put pivot back in the right position).
class Solution { private: vector<int> unique; map<int, int> count_map;
public: int partition(int left, int right, int pivot_index) { int pivot_frequency = count_map[unique[pivot_index]]; // 1. Move the pivot to the end swap(unique[pivot_index], unique[right]);
// 2. Move all less frequent elements to the left int store_index = left; for (int i = left; i <= right; i++) { if (count_map[unique[i]] < pivot_frequency) { swap(unique[store_index], unique[i]); store_index += 1; } }
// 3. Move the pivot to its final place swap(unique[right], unique[store_index]);
return store_index; }
void quickselect(int left, int right, int k_smallest) { /* Sort a list within left..right till kth less frequent element takes its place. */
// base case: the list contains only one element if (left == right) return;
int pivot_index = left + rand() % (right - left + 1);
// Find the pivot position in a sorted list pivot_index = partition(left, right, pivot_index);
//If the pivot is in its final sorted position if (k_smallest == pivot_index) { return; } else if (k_smallest < pivot_index) { // go left quickselect(left, pivot_index - 1, k_smallest); } else { // go right quickselect(pivot_index + 1, right, k_smallest); } }
vector<int> topKFrequent(vector<int>& nums, int k) { // build hash map: element and how often it appears for (int n : nums) { count_map[n] += 1; }
// array of unique elements int n = count_map.size(); for (pair<int, int> p : count_map) { unique.push_back(p.first); }
// kth top frequent element is (n - k)th less frequent. // Do a partial sort: from less frequent to the most frequent, till // (n - k)th less frequent element takes its place (n - k) in a sorted array. // All elements on the left are less frequent. // All the elements on the right are more frequent. quickselect(0, n - 1, n - k); // Return top k frequent elements vector<int> top_k_frequent(k); copy(unique.begin() + n - k, unique.end(), top_k_frequent.begin()); return top_k_frequent; } };
Difficulty: medium Topics: Hash Table, String, Sliding Window
Given a string s, find the length of the longest substring without repeating characters.
Example 1: Input: s = “abcabcbb” Output: 3 Explanation: The answer is “abc”, with the length of 3.
Example 2: Input: s = “bbbbb” Output: 1 Explanation: The answer is “b”, with the length of 1.
Example 3: Input: s = “pwwkew” Output: 3 Explanation: The answer is “wke”, with the length of 3. Notice that the answer must be a substring, “pwke” is a subsequence and not a substring.
Solution
It’s easy to come up with a O(n^2) approach. Just check the length of longest substring starting from 0 to end.
O(n) approach needs more thinking:
int lengthOfLongestSubstring(string s) {
map<char, int> charMap; int start = -1; int maxLen = 0;
for (int i = 0; i < s.size(); i++) { if (charMap.count(s[i]) != 0) { start = max(start, charMap[s[i]]); } charMap[s[i]] = i; maxLen = max(maxLen, i-start); }
return maxLen; }
This puts the index of where characters appears in a hashmap. So as we iterate from 0 to end, we can know where that character appeared last time and find the length. Each time we recalculate the max.
Reflection
interesting concept to blackbox:
whenever finding a maximum value through iteration, let’s use maxval = max(maxval, newval)
use hashmap to store the value and its frequency, or value and index.
If the value is a character or linear sequence number, it can be stored in an array as well. But using hashmap can be more efficient space-wise.