Unfortunately on December I got Influenza A which lasted for 2 weeks + I had finals 😦 so I had a pause since 12th.
After that I felt the need to learn C++ more so I have been studying C++ and some concepts from C these days. I learned most things in C++ so now I am back to problem solving in January. I am writing C++ study notes in google docs and it’s 51 pages now.
Learning low level programming has been really helpful and now I understand better things like TCO (tail call optimization) runtime stack mechanism and foundational concepts in data structures.
For two strings s and t, we say “t divides s” if and only if s = t + ... + t (i.e., t is concatenated with itself one or more times).
Given two strings str1 and str2, return the largest string x such that x divides both str1 and str2.
I initially solved this like this:
string gcdOfStrings(string str1, string str2) { int minlen = min(str1.size(), str2.size()); // check if one is substring of another. if not, return "". if (str1.substr(0, minlen) != str2.substr(0, minlen)) { return ""; } for (int i = minlen; i > 0; i--) { // if str1 and str2 are not divisible by i, pass if (! (str1.size() % i == 0 && str2.size() % i == 0)) { continue; } // check if GCD is correct string GCD = str1.substr(0, i); for (int j = 0; j < str1.size(); j+=i) { if (GCD != str1.substr(j, i)) goto pass; } for (int j = 0; j < str2.size(); j+=i) { if (GCD != str2.substr(j, i)) goto pass; } return GCD; pass: ; } return ""; }
But there was a simpler logic:
str1 and str2 have a gcd iffstr1+str2 == str2+str1
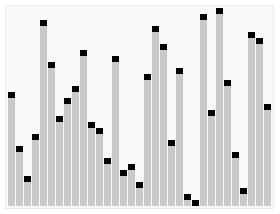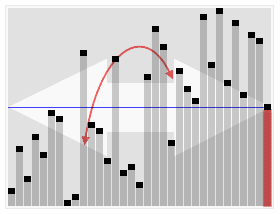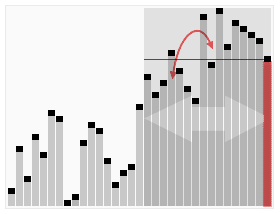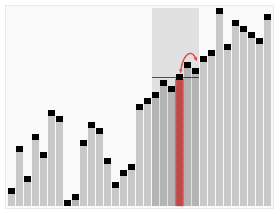
I was solving 169. Majority Element and was struggling to find a one passalgorithm with O(1) space (these are called streaming algorithms). The best I could figure out was in O(n^2) time + O(1) space or O(nlogn) time + O(n) space. But then I saw this mind-blowing one pass approach called MJRTY – Vast Majority Vote Algorithm by Boyer and Moore.
The approach becomes evident with the image below:
We start counting the first element, if a different element appears, instead of start counting that, we decrease the current count. When count becomes 0, we start counting whatever element we encounter next. At the end of the iteration, what we are left with is the majority element.
This only works when an element appears more than n/2 times through the array. The why is pretty intuitive and logical.
Implementation
int majorityElement(vector<int>& nums) { int x, cnt = 0; for (int i = 0; i < nums.size(); i++){ if (cnt == 0){ x = nums[i]; cnt++; } else{ if (nums[i] == x) cnt++; else cnt--; } } return x; }
or faster if written like this:
int majorityElement(vector<int>& nums) { int x = nums[0]; int cnt = 1; for(int i=1;i<nums.size();i++){ if(nums[i] == x){ cnt++; } else{ cnt--; } if(cnt == 0){ x = nums[i]; cnt = 1; } } return x; }
But this has drawbacks. Memory is wasted every time we dequeue.
Thus, need a circular queue.
Circular Queue
fixed-size array, 2 pointers indicating head and tail. Goal is to reuse the wasted storage.
In designing a DS, it’s good to have as few attributes as possible and maintain a simple manipulation logic. Sometimes, there can be some redundancy to minimize time complexity.
Attributes:
queue: fixed size array.
headIndex: integer which indicates the current head element
count: the current length. with `headIndex`, we can locate the tail element.
capacity: max number of elements that can be held in the queue. With this, we reduce TC for calling len(queue).
class MyCircularQueue { private: vector<int> data; int head; int tail; int size; public: MyCircularQueue(int k) { data.resize(k); head = -1; tail = -1; size = k; } bool enQueue(int value) { if (isFull()) { return false; } if (isEmpty()) { head = 0; } tail = (tail + 1) % size; data[tail] = value; return true; } bool deQueue() { if (isEmpty()) { return false; } if (head == tail) { head = -1; tail = -1; return true; } head = (head + 1) % size; return true; } int Front() { if (isEmpty()) { return -1; } return data[head]; } int Rear() { if (isEmpty()) { return -1; } return data[tail]; } bool isEmpty() { return head == -1; } bool isFull() { return ((tail + 1) % size) == head; } };
Hoare’s selecting algorithm is a textbook algorithm used to solve “find kth something”: kth smallest, kth largest, kth most frequent, kth less frequent, etc.
In a hashmap of <element, frequency>, select a random pivot point and use a partition scheme to place the pivot into a position where less frequent elements come to left side of pivot and more or equally frequent comes to the right.
If pivot index is N-k, there are k elements to the right side and all those are more or equally frequent elements, so return them. Else, choose the side of the array to proceed recursively.
Lomuto’s Partition Scheme
places elements >= pivot in the right side of pivot and elements < pivot in the left side.
swap the pivot with last element (or just start with the end element being pivot)
start a pointer from the left (index 0). Call this store_index.
iterating from 0 to end, if the element is less than pivot val, swap the element with element at store_index. If the element is >= pivot val, just pass.
After the iteration, swap pivot with element at store_index (put pivot back in the right position).
class Solution { private: vector<int> unique; map<int, int> count_map;
public: int partition(int left, int right, int pivot_index) { int pivot_frequency = count_map[unique[pivot_index]]; // 1. Move the pivot to the end swap(unique[pivot_index], unique[right]);
// 2. Move all less frequent elements to the left int store_index = left; for (int i = left; i <= right; i++) { if (count_map[unique[i]] < pivot_frequency) { swap(unique[store_index], unique[i]); store_index += 1; } }
// 3. Move the pivot to its final place swap(unique[right], unique[store_index]);
return store_index; }
void quickselect(int left, int right, int k_smallest) { /* Sort a list within left..right till kth less frequent element takes its place. */
// base case: the list contains only one element if (left == right) return;
int pivot_index = left + rand() % (right - left + 1);
// Find the pivot position in a sorted list pivot_index = partition(left, right, pivot_index);
//If the pivot is in its final sorted position if (k_smallest == pivot_index) { return; } else if (k_smallest < pivot_index) { // go left quickselect(left, pivot_index - 1, k_smallest); } else { // go right quickselect(pivot_index + 1, right, k_smallest); } }
vector<int> topKFrequent(vector<int>& nums, int k) { // build hash map: element and how often it appears for (int n : nums) { count_map[n] += 1; }
// array of unique elements int n = count_map.size(); for (pair<int, int> p : count_map) { unique.push_back(p.first); }
// kth top frequent element is (n - k)th less frequent. // Do a partial sort: from less frequent to the most frequent, till // (n - k)th less frequent element takes its place (n - k) in a sorted array. // All elements on the left are less frequent. // All the elements on the right are more frequent. quickselect(0, n - 1, n - k); // Return top k frequent elements vector<int> top_k_frequent(k); copy(unique.begin() + n - k, unique.end(), top_k_frequent.begin()); return top_k_frequent; } };
Difficulty: medium Topics: Hash Table, String, Sliding Window
Given a string s, find the length of the longest substring without repeating characters.
Example 1: Input: s = “abcabcbb” Output: 3 Explanation: The answer is “abc”, with the length of 3.
Example 2: Input: s = “bbbbb” Output: 1 Explanation: The answer is “b”, with the length of 1.
Example 3: Input: s = “pwwkew” Output: 3 Explanation: The answer is “wke”, with the length of 3. Notice that the answer must be a substring, “pwke” is a subsequence and not a substring.
Solution
It’s easy to come up with a O(n^2) approach. Just check the length of longest substring starting from 0 to end.
O(n) approach needs more thinking:
int lengthOfLongestSubstring(string s) {
map<char, int> charMap; int start = -1; int maxLen = 0;
for (int i = 0; i < s.size(); i++) { if (charMap.count(s[i]) != 0) { start = max(start, charMap[s[i]]); } charMap[s[i]] = i; maxLen = max(maxLen, i-start); }
return maxLen; }
This puts the index of where characters appears in a hashmap. So as we iterate from 0 to end, we can know where that character appeared last time and find the length. Each time we recalculate the max.
Reflection
interesting concept to blackbox:
whenever finding a maximum value through iteration, let’s use maxval = max(maxval, newval)
use hashmap to store the value and its frequency, or value and index.
If the value is a character or linear sequence number, it can be stored in an array as well. But using hashmap can be more efficient space-wise.
Hello. I’m writing this at 5:00 AM. This month was somewhat busy, but since November 11, when I decided to commit at least 1 hour to PS every day, I have been keeping it. No matter if I have a midterm tomorrow, an internship application due, or if I’ve slept only 3 hours and my brain is not working, I just sit down for an hour. It’s inefficient at times, but it’s symbolic of my commitment to not losing track. I hope I maintain this pace next month too.
I often get scared doing PS/CP since this is definitely a field where effort can’t win talent and I doubt if I have talent. Oftentimes I think “what if I just spend all this time on learning full-stack dev or machine learning”? If there is someone who have done CP and decided to go to data science or quant field, I want to ask “How do you overcome the fear stemming from spending time on uncertain things?” But anyways there is no going back.
Well. This was reflection for this month. Thank you for reading whoever reading this. I don’t usually share this blog to anyone I know because I want to show them when I have a solid result and not the process.
Given an array of integers nums and an integer target, return indices of the two numbers such that they add up to target.
You may assume that each input would have exactly one solution, and you may not use the same element twice.
You can return the answer in any order.
Example 1:Input: nums = [2,7,11,15], target = 9 Output: [0,1] Explanation: Because nums[0] + nums[1] == 9, we return [0, 1].
Example 2:Input: nums = [3,2,4], target = 6 Output: [1,2]
Example 3:Input: nums = [3,3], target = 6 Output: [0,1]
Solution
While storing the numbers in hashmap, check if the complementary (target – number) is in the hashmap.
Note that hashmap[nums[i]] = i;should not be before the part where we search for comp. This is because search for comp should be done in values previously put in, not including the current value.
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> hashmap;
vector<int> res;
for (int i = 0; i < nums.size(); i++){
int comp = target - nums[i];
if (hashmap.count(comp) > 0){
res = {hashmap[comp], i};
return res;
}
hashmap[nums[i]] = i;
}
return res;
}
// 3. insert a new (key, value) pair or update the value of existed key
hashmap[1] = 1;
hashmap[1] = 2;
// 4. get the value of a specific key
hashmap[1]
// 5. delete a key
hashmap.erase(2);
// 6. check if a key is in the hash map
if (hashmap.count(2) <= 0);
// 7. get the size of the hash map
hashmap.size()
// 8. iterate the hash map
for (auto it = hashmap.begin(); it != hashmap.end(); ++it) {
cout << it->first << "," << it->second << endl;
}
// 9. clear the hash map
hashmap.clear();
// 10. check if the hash map is empty
if (hashmap.empty())
Iterating over list of keys:
for (Type key : keys) {
if (hashmap.count(key) > 0) {
if (hashmap[key] satisfies the requirement) {
return needed_information;
}
}
// Value can be any information you needed (e.g. index)
hashmap[key] = value;
}
// Comparator function to sort pairs by second value bool sortByVal(const std::pair<int, int>& a, const std::pair<int, int>& b) { return (a.second < b.second); }
int main() { // Define a map std::map<int, int> myMap = {{1, 40}, {2, 30}, {3, 60}, {4, 20}};
// Copy elements to a vector of pairs std::vector<std::pair<int, int>> vec; for (auto& it : myMap) { vec.push_back(it); }
// Sort the vector by value std::sort(vec.begin(), vec.end(), sortByVal);
// Print the sorted vector for (auto& it : vec) { std::cout << it.first << ": " << it.second << std::endl; }
return 0; }
Tips
When counting frequency, don’t need to check if the hashmap[x] exists.
// don't do this: if (hashmap.count(x) > 0) hashmap[x]++; else hashmap[x] = 1; // do this: hashmap[x]++;
// same for adding up the frequency: for (...){ sum += hashmap[x]; }
Difficulty: medium Topics: Array, Two Pointers, Binary Search, Sliding Window
Given a sorted integer array arr, two integers k and x, return the k closest integers to x in the array. The result should also be sorted in ascending order.
An integer a is closer to x than an integer b if:
|a - x| < |b - x|, or
|a - x| == |b - x| and a < b
Example 1:Input: arr = [1,2,3,4,5], k = 4, x = 3 Output: [1,2,3,4]
Example 2:Input: arr = [1,2,3,4,5], k = 4, x = -1 Output: [1,2,3,4]
Solution
This was a question that I struggled a lot. It was harder than usual binary search problems. There are many ways to think for this problem.
Solution 1: O(N⋅log(N)+k⋅log(k))
compute the distances between the elements and x, sort it and display the first k elements. When displaying it, sort again.
returnvector<int>(arr.begin() + l, arr.begin() + l + k);
}
};
There is another way of seeing this: (from lee215’s solution post)
We compare the distance between x - A[mid] and A[mid + k] - x If we assume A[mid] ~ A[mid + k] is sliding window
case 1: x – A[mid] < A[mid + k] – x, need to move window go left ——-x—-A[mid]—————–A[mid + k]———-
case 2: x – A[mid] < A[mid + k] – x, need to move window go left again ——-A[mid]—-x—————–A[mid + k]———-
case 3: x – A[mid] > A[mid + k] – x, need to move window go right ——-A[mid]——————x—A[mid + k]———-
case 4: x – A[mid] > A[mid + k] – x, need to move window go right ——-A[mid]———————A[mid + k]—-x——
Reflection
I think whenever using binary search, I should think about based on what criteria I will choose the left side or the right side given a mid point. This was particularly harder because I didn’t think of finding the left bound. Let’s remember that when finding a range, I can try to find only left or right bound.